Table of Contents
Resumen ejecutivo
Los coronavirus son una familia de virus que suelen causar enfermedades en animales, aunque algunos pueden afectar también a humanos. En las personas pueden producir infecciones respiratorias que pueden ir desde un resfriado común hasta enfermedades más graves. En el 80% de los casos, la infección por este nuevo coronavirus, denominado oficialmente SARS-Cov-2, produce síntomas respiratorios de carácter leve. Con el nombre de COVID-19 se denomina la enfermedad respiratoria producida por este virus. Hasta el día de hoy (May 5) se han confirmado en nuestro país 26,025 casos y 2,507muertes. Mucho se ha hablado de la importancia del distanciamiento social ya que, de no hacerlo, se traduciría en hospitales saturados y tristemente en un gran número de muertes.
Debido a la importancia de lo anterior, decidí escribir este post con los siguientes objetivos:
- Resumir la situación de la epidemia por COVID-19 en nuestro país, tomando en cuenta el funcionamiento del sistema de vigilancia epidemiológico en nuestro país.
- Estimar el impacto que han tenido las diferentes medidas de mitigación realizadas por el gobierno federal a través de las muertes observadas por COVID-19 en nuestro país mediante un modelo jerárquico bayesiano propuesto aquí: Este modelo también estimó que tan rápido se infectan las personas (número efectivo de reproducción) y el total de pacientes infectados con SARS-COV2 a través del tiempo. Dado que el modelo estima el efecto que han tenido las medidas decretadas por el gobierno federal, fue posible predecir el número de muertes acumuladas que pueden ocurrir en los siguientes 7 días.
Los resultados son los siguientes: el 0.49% (95% CrI: 0.13% - 1.05%) de la población en nuestro país se encuentra infectada con SARS-COV2 hasta May 5. Desde que se exhortó al distanciamiento social mediante la campaña “Susana Distancia”, el número de reproducción efectivo esperado fue de 1.3 (95% CrI: 0.2 - 1.7), lo que implica que una persona infecta a 1.3 personas.
De acuerdo a los resultados, el número acumulado de muertes seguirá incrementando en los próximos 7 días. Si bien se observó que extender “Susana Distancia” ha logrado reducir el número de muertes, estas medida de mitigación no ha logrado disminuir lo suficiente el número efectivo de reproducción1. Estas estimaciones son de gran utilidad ya que podrán servir para poder realizar estimaciones del uso de recursos por tratar COVID-19, especialmente sería de gran interés poder conocer si el número de ventiladores serán suficientes en los siguientes meses.
Introducción
Este post nace después de 4 semanas de distanciamiento social en Toronto, Canadá. Para los que no me conocen, actualmente soy doctorante en la Universidad de Toronto donde mi línea de investigación es el aprendizaje estadístico como herramienta de predicción en enfermedades que tienden a progresar a a través del tiempo (e.g. cáncer). Cuento con una posición de investigador asociado en University Health Network el cual aglomera diferentes hospitales para una mejor colaboración en diferentes temas de investigación.
Es importante notar que este post no ha sido revisado por pares y que mi línea de investigación no es el modelaje de enfermedades infecciosas. Lo que sí he hecho es apoyar a un grupo de investigadores en la provincia de Ontario en Canadá en la creación de modelo para simular la utilización de recursos en hospitales por COVID-19. Este post tiene como objetivo discutir algunos aspectos importantes de la epidemia en nuestro país y por estimar el impacto de las diferentes medidas de mitigación en nuestro país utilizando el número de muertes como nuestra variable observable. El link para el código de este post se encuentre en un repositorio de Github el cuál podrán encontrar al final de este post; las gráficas y el análisis fueron hechos en R, utilizando en su mayoría librerías como dplyr, ggplot2,rstan entre otras.
Epidemia en México
Mucho se ha hablado en las conferencias vespertinas relacionadas a COVID-19 acerca del número de casos nuevos desde que la epidemia llegó a nuestro país y si el gobierno ha hecho pruebas suficientes. Antes de cualquier análisis de la epidemia en México creo que es importante describir algunos aspectos importantes de ésta, como por ejemplo: 1. Cómo funciona el sistema epidemiológico en nuestro país. 2. Cómo se alimenta diariamente el número de casos confirmados.
Sistema epidemiológico en México
El Dr. Hugo López Gatell ha mencionado en reiteradas ocasiones como funciona el sistema centinela en nuestro país (la siguiente entrevista es muestra de lo anterior). A manera de resumen, la idea del programa es que “en vez de recopilar grandes cantidades de datos de calidad deficiente, hay que concentrarse en recopilar datos de buena calidad de un número reducido de centros centinela seleccionados cuidadosamente”, de acuerdo al documento de la OMS actualizado en 2014. El proceso es buscar COVID-19 en pacientes negativos a la prueba de influenza para ver si hay transmisión comunitaria; Alberto Díaz Cayeros hace una descripción de éste y discute posibles fallas que pueden ocurrir al utilizar este sistema.
La vigilancia centinela no es nueva en nuestro país ya que éste fue utilizado para H1N1 en el 2009. ¿Por qué utilizar este sistema y no pruebas masivas como lo hizo Corea del Sur? Creo que es por dos razones: el sistema ha funcionado (H1N1) y es eficiente debido las limitaciones de recursos en salud en nuestro país. Es importante aclarar que estas limitaciones no son nuevas y es producto de un porcentaje muy bajo del gasto en el sector salud como porcentaje del PIB durante varios años de acuerdo a la OCDE.
Casos confirmados
El 28 de febrero fue confirmado el primer paciente con COVID-19 en nuestro país. Desde el 23 de marzo se han modificado los criterios operacionales para la vigilancia epidemiológica de COVID-19. Como se ha mencionado en diferentes medio de comunicación (nota aquí) la definición es la siguiente:
Caso sospechoso - Persona de cualquier edad que en los últimos siete días haya presentado al menos dos síntomas de tos, fiebre o cefalea, es decir, dolor de cabeza intenso y persistente y que esté acompañado de los siguientes signos: dificultad para respirar, hinchazón en articulaciones con dificultad de movimiento, dolor muscular, ardor de garganta, rinorrea, conjuntivitis y dolor de tórax.
Caso confirmado - Persona que cumpla lo anterior y que cuente con confirmación del InDRE.
Asimismo, se modificó el porcentaje de muestreo para vigilar los casos de COVID-19. Solo se realizará la prueba al 10% de los casos sospechosos sin síntomas o síntomas leves. A su vez, se realizará la prueba al 100% de los casos sospechosos con sintomatología grave o que cumplan con la definición infección respiratoria aguda grave (IRAG). Es importante recalcar que el gobierno ha recalcado que todos los casos sospechosos sin importar si se les realizó la prueba deberán de permanecer en aislamiento .
Hace aproximadamente una semana el Dr. López Gatell mencionó que habían hasta 26 mil casos en nuestro país. Esta estimación se logró gracias a la vigilancia centinela ya que este sistema representa una muestra del total de unidades de salud en nuestro país2
Análisis de la epidemia en México
Antes de presentar datos y gráficas me gustaría enfatizar en 2 aspectos importantes al considerar la presentación y análisis de datos de casos confirmados con COVID-19:
- La comparación entre países (e.g. incidencia acumulada) debe de realizarse con mucho cuidado. Esto debido a lo expuesto en la sección anterior; los países tienen distintos sistemas epidemiológicos y diferentes recursos, por lo tanto la cantidad de casos confirmados está en función de la cantidad de pruebas que puedan realizar. Es muy importante recalcar esto ya que esta comparación es la que más noticias engañosas y falsas que al menos yo he encontrado en redes sociales (ver aquí).
- La comparación entre países debe de realizarse desde un punto en común en el tiempo ya que la epidemia entra a cada país en momentos distintos. Esto tiene mucha importancia sobre todo al presentar gráficas e ilustraciones ya sea para mostrar la incidencia (casos nuevos) o incidencia acumulada.
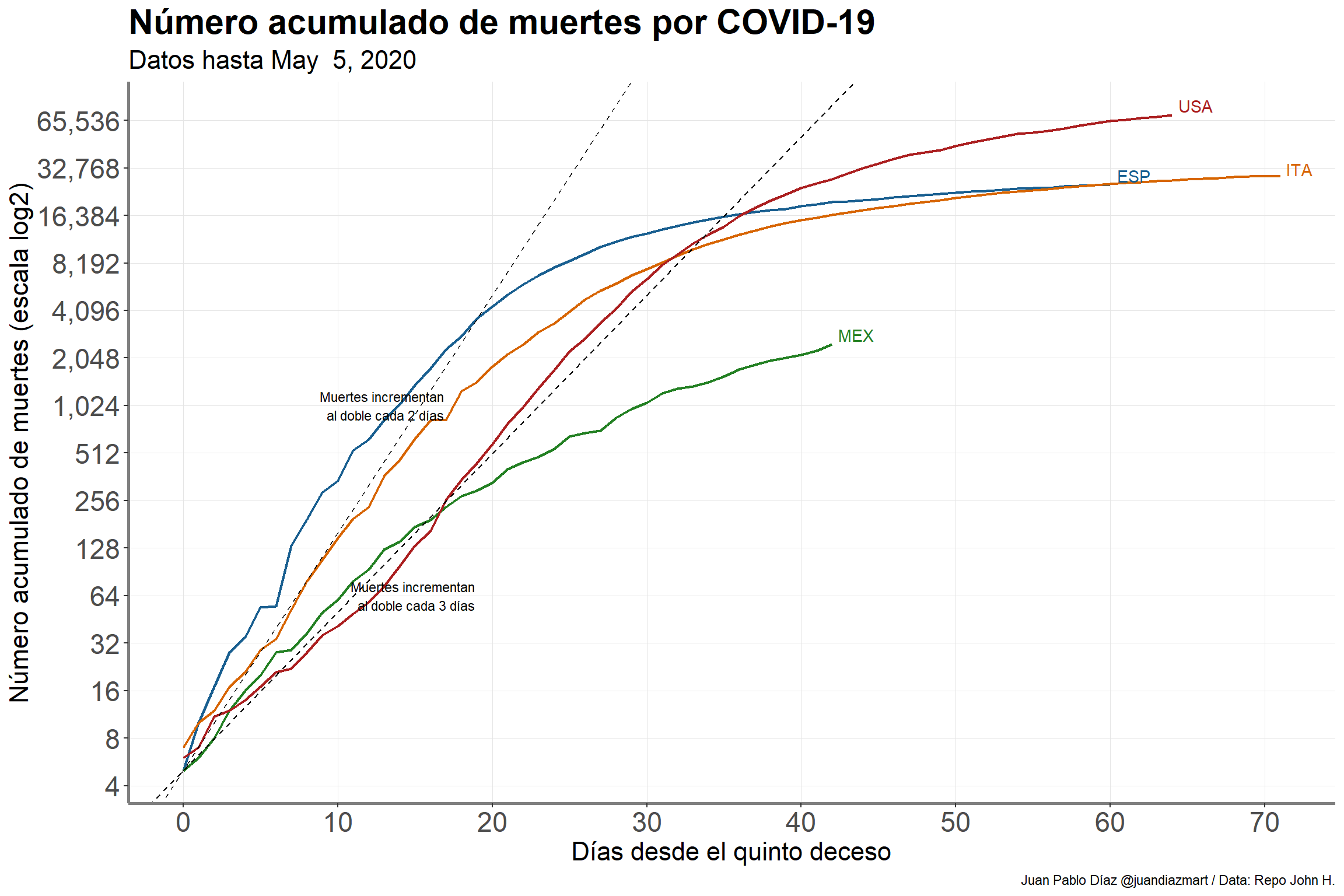
¿Qué sí podemos rescatar cuando comparamos casos confirmados entre diferentes países?. La siguiente gráfica muestra el número de casos confirmados acumulados con COVID-19 desde que se confirmó el paciente número 100. Decidí transformar el eje de las \(y\) al aplicarle el logaritmo base 2; esta transformación ayuda a una mejor interpretación de los datos ya que es más fácil para el lector ver cuanto tiempo se tarda un país en tener el doble de casos confirmados en un periodo determinado de tiempo. Asimismo al transformar los datos la serie de tiempo presenta un comportamiento más lineal.

Muchos de los modelos epidemiológicos se basan en la incidencia de casos confirmados para poder hacer estimaciones y/o proyecciones de diferentes desenlaces en salud, ya sea mortalidad, hospitalizaciones, intubaciones, etc. Una de las grandes limitaciones es el tiempo que pasa entre el momento de la infección y el momento que la prueba resulta positiva. Esto se debe a que entre estos dos momentos hay un periodo de incubación (mediana 6 días [@lauer2020incubation]) y un periodo entre que se toma la prueba y se entrega el resultado de ésta (mediana 9 días [@gob]). Una consecuencia de esto es que los casos confirmados que se presentan día a día son en realidad los casos que se infectaron hace 2 semanas o más. Adicionalmente, el sistema de vigilancia centinela no realiza pruebas a aquellos que no cumplen la definición operacional, implicando que este sistema no logra capturar a todas las personas asintomáticas. Esto pudiera generar diferentes brotes ya que existe evidencia científica relacionada a la transmisión del virus por parte de los que no presentan ningún tipo de síntoma [@Bai]. Debido a estas limitaciones, diferentes investigadores en enfermedades infecciosas han utilizado las muertes observadas como la variable principal para hacer inferencia en diferentes modelos epidemiológicos ([@flaxman2020report]). El razonamiento de este abordaje es que en teoría sí podemos observar las todas las muertes, al menos todas aquellas que ocurrieron en un hospital.
La siguiente gráfica nos ayuda a entender el comportamiento de número de muertes acumuladas en nuestro país desde que se presentó la quinta defunción.
Estimación del número de infectados y del impacto de Susana Distancia.
Debido a la naturaleza e importancia de la enfermedad, diferentes revistas indexadas en el mundo han acelerado su proceso de revisión para poder publicar diferentes artículos académicos referentes al SARS-COV 19. A mí siempre me han llamado la atención aquellos artículos que describen modelos de predicción.
En la sección anterior mencioné que es mejor utilizar el número de muertes si queremos hacer algún tipo de comparación o inferencia. Algunas limitaciones de este número son:
- Posible sub-estimación de muertes por COVID 19 - Esto debido a que habrá casos donde SARS-COV 19 no haya sido identificado.
- Posible retraso en la captura de muertes - Hemos visto en algunas conferencias vespertinas casos donde la confirmación de SARS-COV 19 llega después del fallecimiento.
Estas limitaciones no afectarán ningún modelo o inferencia que se quiera realizar siempre y cuando ambas se mantengan constantes en el tiempo.
¿De qué manera se puede estimar el número de infectados y el impacto de las medidas realizadas por el gobierno federal para incentivar el distanciamiento social? Utilizando la historia natural de la enfermedad. El Imperial College de Reino Unido publicó el 30 de marzo un modelo modelo de predicción de muertes, infectados y efectos de diferentes medidas para “aplanar la curva”. Con el fin de tener una mejor imagen de lo que pasa con COVID-19, el anterior modelo fue adaptado utilizando los datos oficiales reportados en nuestro país. La Figura 1 muestra el modelo de predicción.
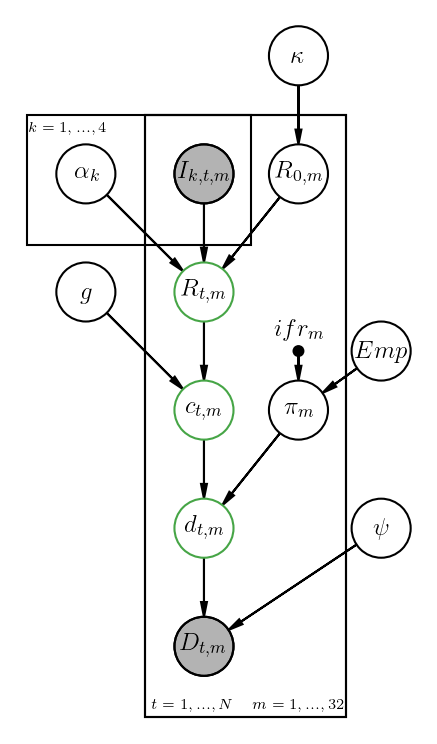
Figure 1: Representación del modelo utilizando grafos causales acíclicos. Se puede observar la relación entre los diferentes parámetros en el modelo.
El modelo utiliza las muertes observadas de acuerdo a los datos oficiales del gobierno de México.La Figura 1 muestra el nivel jerárquico (de abajo hacia arriba) que nos permite relacionar el impacto de diferentes intervenciones (i.e. cierre de escuelas,etc.) y las muertes observadas. Dada la relación que existe entre los diferentes parámetros a estimar, el modelo realiza la inferencia utilizando un enfoque Bayesiano mediante stan, un lenguaje de programación específico para inferencia Bayesiana. La relación entre los parámetros se explica a grandes rasgos a continuación utilizando la misma notación que el modelo original.
Muertes observadas
El número de muertes observadas \(D_{t,m}\) para los días \(t\in1,...,n\) en la región \(m\in1,...,p\) serán obtenidas de fuentes estatales y federales [@gob]. Éstas son modeladas utilizando su valor esperado, es decir, \(d_{t,m}=\mathbf{E}[D_{t,m}]\). El modelo asume que \(D_{t,m}\) tiene una distribución binomial negativa con los siguientes parámetros:
\[D_{t,m}\sim binomial neg\left(d_{t,m},d_{t,m}+\frac{d_{t,m}^2}{\psi}\right)\] \[\psi \sim N^+(0,5)\]
donde \(\psi\) tiene una distribución normal truncada. El número esperado de muertes \(d\) en un determinado día es una función del número de infecciones \(c\) que ocurrieron en días previos. Para poder unir las muertes con los casos infectados, se utiliza la tasa de mortalidad por infección (\(ifr\), infection mortality rate en inglés) que toma en cuenta tanto a los detectados como los no detectados3 y el tiempo que pasa entre la infección y la muerte, la cual denotamos con \(\pi_{m}\). Si bien no hay un dato para las entidades federativas hasta el momento para \(ifr_m\), se puede utilizar lo ya estimado a nivel mundial, el cual es aproximadamente 0.9% [@verity2020estimates]. Esta tasa podrá ser actualizada una vez que nueva evidencia sea publicada con respecto a las distintas entidades federativas.
Con el fin de introducir incertidumbre a esta tasa, asumimos que
\[ifr_{m}^*\sim ifr_{m}(N(1,0.1))\] Donde \(N\) tiene una distribución normal con media 1 y desviación estándar 0.1.
Con base en estudios previos [@baud2020real], el modelo asume que \(\pi_m\) es una suma de dos tiempos independientes: el tiempo de incubación (tiempo entre infección y síntomas) y el tiempo entre síntomas y muerte. Estos tiempos son aleatorios y por lo tanto se les asigna una distribución de probabilidad (Gamma4). Por lo tanto \(\pi_{m}\) está dado por:
\[\pi_{m}\sim ifr_{m}^*((Gamma(5.1,0.86)+Gamma(18.8,0.45))\]
Ahora que ya sabemos que \(\pi_{m}\) representa la distribución entre el tiempo de infección y muerte ajustada por la tasa de mortalidad por infección, se puede relacionar el número esperado de muertes en un determinado día \(d_{t,m}\) con \(\pi_{m}\) de la siguiente manera:
\[d_{t,m}=\sum_{\tau=0}^{t-1} c_{\tau,m}\pi_{t-\tau,m}\]
donde \(c_{\tau,m}\) es el número de nuevas infecciones en el día \(\tau\) y donde \(\pi_{m}\) es discretizado.
Infecciones en el modelo
Hasta ahora he resumido la relación que puede existir entre el número de muertes y el número de infecciones al día \(t\). Para modelar el número de infecciones en el tiempo es necesario especificar el tiempo que pasa entre el inicio de síntomas de una persona y el inicio de síntomas de otra persona infectada por la primera (en inglés se conoce como serial interval). De acuerdo a la literatura [@zhou2020clinical] el promedio de este tiempo ronda entre los 4 días y 8 días, por lo que el modelo asume que éste tiene una distribución gamma5 con los siguientes parámetros:
\[ g \sim Gamma(6.5,0.62)\]
El número de infecciones \(c_{t,m}\) al día \(t\) está dada por el siguiente proceso de renovación [@branch]:
\[c_{t,m}=R_{t,m}\sum_{\tau=0}^{t-1} c_{\tau,m} g_{t-\tau,m}\]
donde \(g\) también es discretizada. Lo anterior implica que las infecciones al día de hoy dependen de las infecciones en días pasados, ponderadas por la distribución \(g\). Esta ponderación es ajustada por el numero efectivo de reproducción \(R_{t,m}\). Éste número cambia con respecto al tiempo debido a que la implementación de diferentes medidas de mitigación en teoría hará que éste disminuya y por lo tanto haya menos contagios.
La idea es empezar con un número de reproducción basal \(R_{0,m}\) y que este se irá modificando en el tiempo debido a la implementación de diferentes intervenciones en las regiones.
Para facilitar la estimación de \(R_{t,m}\), se utiliza un predictor lineal que modifique \(R_{t,m}\) a partir de un valor inicial \(R_{0,m}\), tomando en cuenta que \(R_t\) solo toma valores positivos. Por lo tanto el número efectivo de reproducción \(R_{t,m}\) es una función de la implementación de cada intervención al día \(t\):
\[R_{t,m}=R_{0,m}exp(-\sum_{k=1}^{4}\alpha_{k}I_{k,t,m})\]
donde I es una variable indicadora donde toma el valor de 1 y la intervención \(k\) es implementada \(k=1,...,4\) y 0 si no.
El modelo utiliza las siguientes intervenciones de mitigación:
Cancelación de eventos públicos - Se asume como el día (Marzo 17) en que el gobierno de la CDMX decidió cancelar todos los eventos públicos en la ciudad.
Cierre de escuelas - Se asume como el día (Marzo 21) en que la UNAM suspendió clases clases.
Exhortación al distanciamiento social - Inicio de Susana Distancia (Marzo 23).
Exentensión de la Jornada Nacional de Sana distancia - 16 de abril.
Asimismo:
\[\alpha_{k}\sim Gamma(.5,1)\]
La distribución de \(R_{0,m}\) fue asumida con base en la evidencia previa [@zhang]:
\[R_{0,m}\sim Normal(3.4,|\kappa|),\kappa\sim Normal(0,0.5)\]
Finalmente el modelo asume que las nuevas infecciones ocurren 20 días antes de que el país haya acumulado 10 muertes observadas. A partir de esta fecha, simulamos 6 días seguidos de infecciones \(c_{1,m},...,c_{6,m}\sim Exponencial(\iota)\), donde \(\iota\sim Exponencial(0.3)\), Estas infecciones se infieren con nuestra distribución posterior.
Resultados
El modelo estima que para May 5, el número acumulado de infectados por SARS-COV2 en nuestro país es de 618,813 (95% CrI: 171,465 - 1,340,683) (ver Figura 2). Lo anterior representa al 0.49% (95% CrI: 0.13% - 1.05%) de la población total en nuestro país, utilizando los datos de CONAPO para 2020 (127 millones de mexicanos aproximadamente).
¿Cómo podemos saber si nuestra modelo estima de manera correcta nuestros resultados? Una forma es comparar los resultados de nuestro modelo con las estimaciones hechas con el sistema centinela por parte del gobierno federal. El 9 de abril se presentó una estimación de los casos totales al finalizar la semana epidemiológica 13. que concluyó el 28 de marzo de acuerdo a los documentos técnicos de la Dirección de Epidemiología. Nuestro modeló estimo que para el 28 de marzo habían 39,090 casos acumulados (95% CrI: 27,013 - 57,373), mientras que para esa fecha el modelo centinela estimó 26,519 casos. La diferencia entre uno y otro se debe a lo comentado en la introducción: el sistema centinela no toma muestras de los asintomáticos. Nuestra estimación se basa en la relación que hay entre infectados y la tasa con la que mueren éstos \(ifr\).
Figure 2: Número acumulado de infectados con SARS-Cov-2, observados y predichos. La región azul representa la incertidumbre de nuesta estimación (línea negra)
Al inicio de la epidemia en México, el número efectivo de reproducción \(R_t\) (ver Figura 2) era de 3.4 (95% CrI: 2.2 - 5.2). Después de que el gobierno extendió “Susana Distancia” el 16 de abril, éste descendió a 1.3 (95% CrI: 0.2 - 1.7).
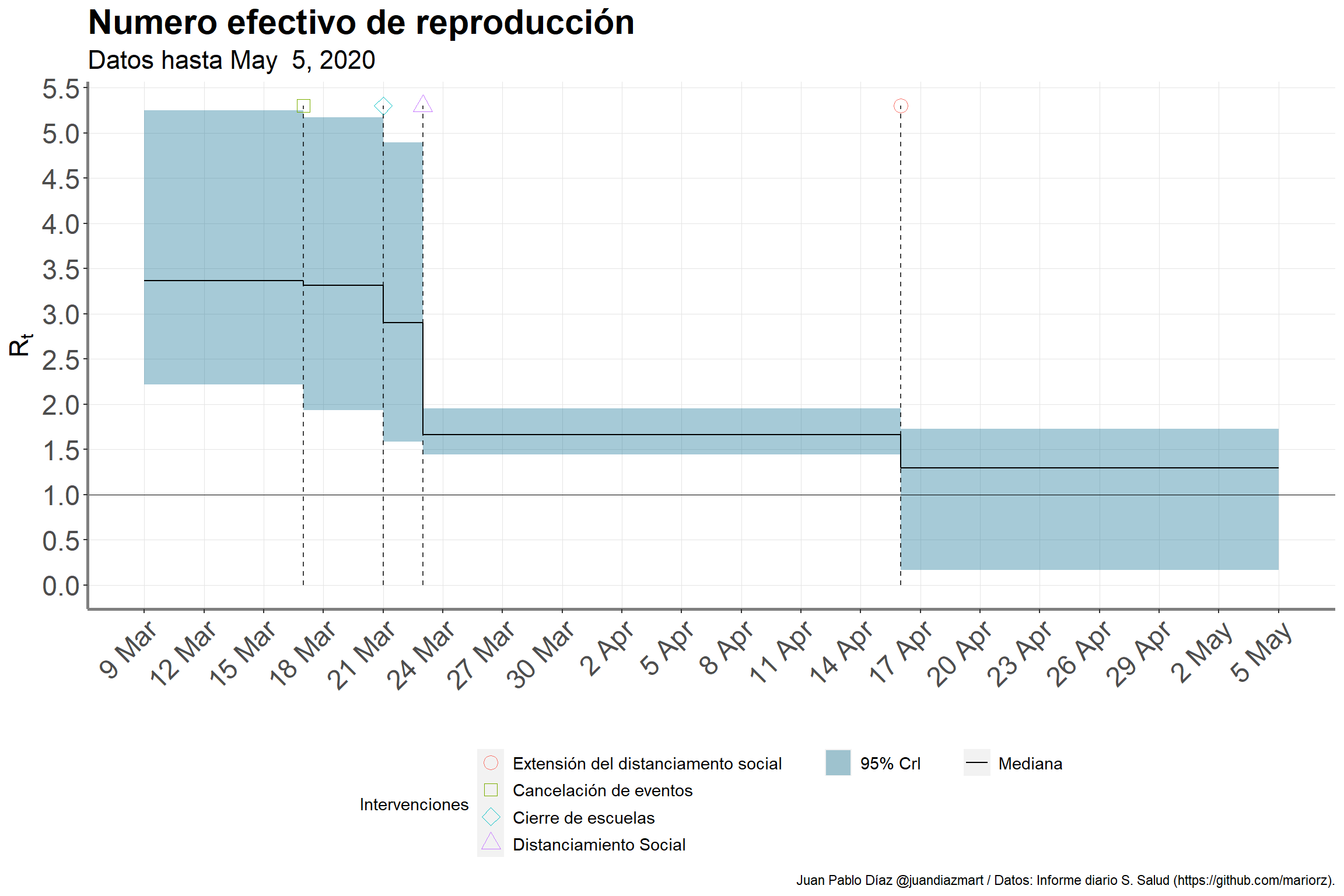
Figure 3: Efecto de las intervenciones en el número efectivo de reproducción
Una de las ventajas de este modelo es que nos permite hacer predicciones del número acumulado de muertes, utilizando el \(R_t\) estimado en el modelo y su contrafactual6 (\(R_t\) al inicio de la epidemia en nuestro país); estas predicciones se muestran en la Figura 4. Con estos resultados es posible estimar cuantas muertes se han evitado hasta el día de hoy, lo anterior se obtiene al calcular la diferencia entre ambas predicciones (región azul menos región roja de la Figura 4 en May 5). Gracias a las medidas de mitigación se han podido evitar 109,826 (95% CrI: 26,938 - 673,865) muertes. Con lo anterior fue posible también hacer una proyección a 7 días del número acumulado de muertes.
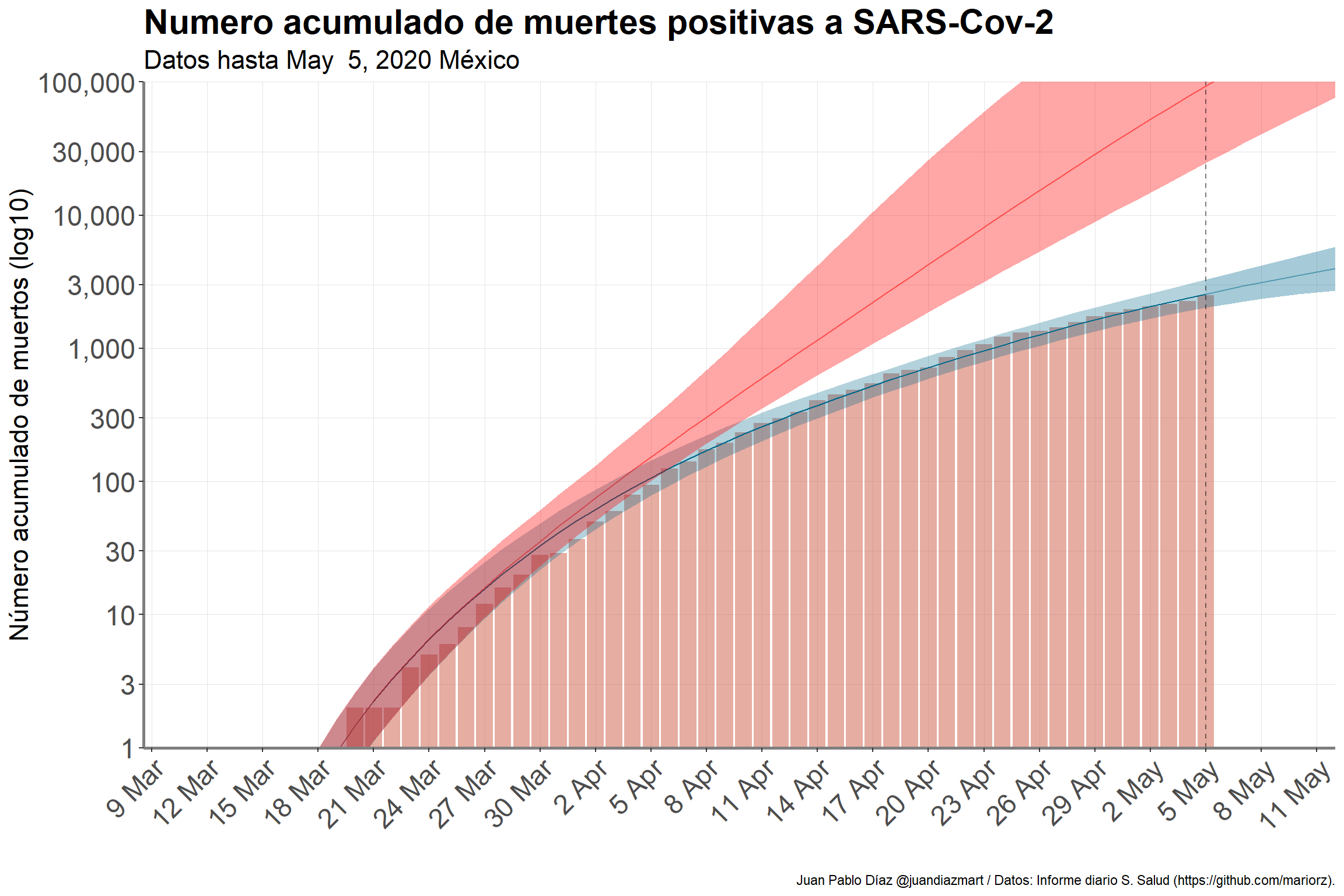
Figure 4: Número acumulado de muertes por COVID-19, observados y predichos. La región azul representa la predicción de nuestro modelo utilizando el número efectivo de reproducción de la figura anterior. En contraste la región roja representa la predicción de muertes utilizando el número de reproducción basal, es decir, al inicio de la epidemia.
Por hacer
- Reparametrizar algunos parámetros para incluir otras covariables.
- Predictive checks.
Lo ideal es que éste se encuentre debajo de uno↩
El muestreo estadístico se encarga de seleccionar metodológicamente una muestra para poder hacer estimaciones a nivel poblacional.↩
La tasa de letalidad solo contempla a los detectados mientras la tasa de mortalidad por infección contempla a todas las personas infectadas.↩
Parametrizada con la media de la distribución y su coeficiente de variación.↩
Misma parametrización con media y cv.↩
Lo que pudo haber ocurrido↩